
Today we’re introducing Astro AI, a production-grade control plane for AI agents. Astro AI makes agents discoverable, governable, and deployable as first-class digital workers inside your organization.
AI agents are no longer experiments running in sandboxes. They’re being deployed with credentials, production data access, and the authority to take action on behalf of humans. An agent with production access is a non-deterministic program with write permissions to your business, and that changes the engineering problem entirely. You can’t YOLO your way to a Clawdbot and trust it with your production data; that’s a recipe for destroying your credibility and your business.
From building to shipping, to scaling and operating, we learned a lot by doing. As soon as agents moved beyond demos and into real environments, we discovered something fundamental: an agent is a distributed system with a probabilistic core.
Moreover, the same issues surfaced repeatedly. There was no standardized way to describe a complete working agent. Inference logic lived in one place, guardrails in another, tool definitions somewhere else. Observability was inconsistent. Ownership was unclear. Discoverability was poor. Some agents were embedded in chat interfaces, others in bespoke web interfaces and widgets. Removing an unsafe or ineffective agent required tribal knowledge. We needed a system that treated agents as first-class operational assets.
This is why we’re launching Astro AI, founded on five pillars that clearly emerged from our AI transformation.
1. The Agent Is a System (Not a Prompt)
An agent is an orchestration layer around a model. The language model provides reasoning capability, but the agent itself encompasses the execution graph that coordinates that reasoning, the tool invocation logic that translates intent into API calls, the prompts and structured inputs that guide behavior, the state transitions, retries, branching logic, memory boundaries, and the error handling paths that determine what happens when things go wrong.
Maintaining confidence in a non-deterministic engine requires visibility into how it operates. That means being able to inspect the execution graph, trace tool calls in order, understand how data moved through the system, and see why a particular decision was made. Without that visibility, trust degrades quickly, and it’s not because the model is incapable, but rather, because the surrounding system is opaque.
Treating agents as simple prompt wrappers is a category error. They’re distributed systems with probabilistic cores.
2. Data is the Substrate, Context is the Working Memory
Agents do not inherently understand your business. They ingest representations of it as data, and what they ingest determines what they amplify. That context functions as the working memory of the organization, injected at runtime—structured data representing your knowledge, policies, history, constraints, and current state.
Treating ingestion as a thin layer that simply pipes documents into a vector store misses the point. Retrieval boundaries, schema design, source versioning, temporal freshness, and data lineage directly shape the reasoning surface available to the agent. Context is the frame within which decisions are made.
When context is poorly structured or loosely governed, the agent doesn’t just produce incorrect outputs. Worse, it produces confident, automated, and scalable misalignment. Without clear boundaries around what constitutes valid context (e.g., what is authoritative, what is stale, what is role-specific, what is environment-specific) reasoning drifts.
What the agent can see defines what it can infer. What it can infer defines what it can do. Most agents start with unstructured data—PDFs, wikis, Slack threads, documentation sites. This is where demos shine and people get fascinated by what’s possible. But reliability over time requires discipline. Production agents need curated knowledge bases, structured ingestion pipelines, and clearly defined sources of truth. They must operate over shaped information, not raw entropy.
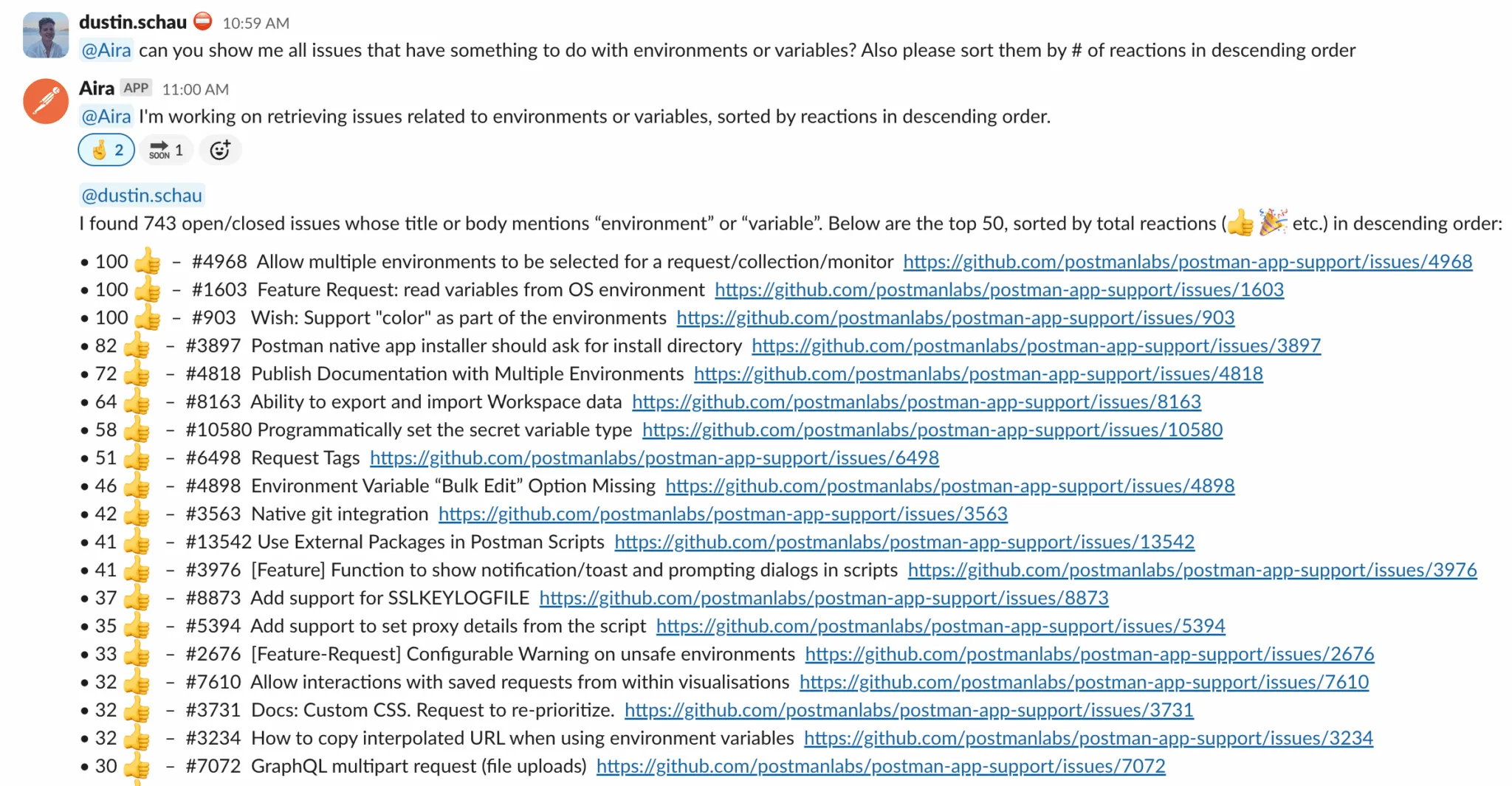
The GitHub analysis agent described earlier illustrates this principle. Rather than operating over raw issue threads, it ingests structured metadata (issue labels, correlation patterns, activity timelines, and prioritization signals) that is organized into a queryable knowledge base, making analysis reliable and actionable.
The thrill of unstructured ingestion fades quickly in production. What matters is not that an agent can ingest everything, but that it ingests the right things in the right structure. The data you shape becomes the working memory that determines how a system acting on your organization’s behalf can reason and act. Context is not ambient. It is constructed, governed, and injected deliberately.
3. Determinism Guards Non-Determinism
Large language models are probabilistic by design. Modern software, by contrast, was built on determinism.
For decades, our entire digital abstraction layer has rested on a simple foundation: a world of 0s and 1s, true and false, deterministic state transitions that behave the same way every time given the same input. The reliability of modern systems (e.g., databases, payment processors, distributed services, operating systems) depends on that bedrock assumption. Determinism was the cornerstone of how we engineered trust into software.
AI disrupts this assumption. At the core of an agent is a reasoning engine that does not guarantee identical outputs for identical inputs. It operates in probabilities, not certainties. That flexibility is what makes it both powerful and dangerous when embedded inside deterministic systems.
If the core is probabilistic, the perimeter must be rigorously deterministic. Guardrails are how that boundary is enforced. They validate inputs and outputs against schemas, apply declarative policy rules, constrain which tools may be invoked and under what conditions, enforce rate limits and execution budgets, and introduce approval workflows when autonomy must yield to oversight. They provide auditability, intervention points, and kill switches when behavior deviates from acceptable norms.
The goal is to contain non-determinism within explicit operational limits so that probabilistic reasoning can coexist with deterministic systems. Autonomy without constraints is unmanaged risk introduced into infrastructure that was never designed to absorb it.
4. Your APIs Must Be AI-Ready
Agents magnify the strengths and weaknesses of the systems they integrate with. They call APIs more frequently than humans, chain them together in novel sequences, and operate at speeds that expose edge cases quickly.
When an agent calls an API, it’s doing so on behalf of a user, often with that user’s credentials, identity, and permissions. One has to consider failed API calls in terms of the outcomes and real-world impact they may carry. Examples of errant behavior may be a customer email sent to the wrong person, a database record deleted, or a charge processed incorrectly. The consequences are real, immediate, and attributed to the human whose authority was delegated.
If APIs are ambiguously specified, lack pagination or rate limits, have unclear authorization scopes, don’t support service identities, or provide limited observability, connecting them to an autonomous agent compounds fragility. The friction we once tolerated becomes systemic instability and a liability.
This changes what “AI-ready” means. APIs must support i) explicit delegation of authority, with clear scopes that define what an agent can do versus what requires human approval, ii) service identities that distinguish agent actions from direct user actions, and iii) audit trails that show who authorized what. APIs must also be well-documented, versioned, rate-limited, and observable. When agents operate with credentials in production, API design becomes a first-order architectural concern.
5. Production-grade Agents Have a Lifecycle
Agents are deployable infrastructure units, and infrastructure requires discipline. A production-grade agent must be packaged as a coherent artifact that includes its inference definition, execution graph, ingestion configuration, guardrails, observability hooks, and deployment metadata. It must be versioned, promoted across environments, monitored in runtime, upgraded safely, audited historically, and decommissioned cleanly when necessary.
It must also support customization without fragmentation, model substitution without structural collapse, and portability across runtimes without rewriting core logic. It must integrate with local development workflows while remaining viable in distributed production environments.
Agents also have a lifecycle that must be managed, with distinct lifecycle operations performed by different personnel:
- Agent builders define inference flows, tool contracts, data boundaries, and policy constraints.
- Agent supervisors monitor execution, enforce guardrails, inspect failures, and intervene when necessary.
- Agent hiring managers decide which agents are enabled, which are redundant, and which fail to justify their cost.
- Augmented humans rely on agents to extend their capabilities, using AI as a force multiplier.
These operations require explicit ownership and lifecycle management to ensure accountable automation, and to realize the promise of the AI transformation.
Introducing Astro AI
Astro AI is a platform for discovering, managing, and operating AI agents in production. It operationalizes the architectural constraints we learned the hard way.
At its core, Astro AI defines a standardized, open way to describe and package a complete agent. A packaged agent includes its data substrate, memory manager, execution graph, tool contracts, guardrail policies, observability configuration, and deployment metadata. An agent becomes a portable, versioned artifact instead of a loose collection of prompts and scripts.
Astro AI provides a registry where agents can be published, discovered, hired, and fired. Agents built by individuals, teams, or entire organizations become visible and manageable assets. Ownership is explicit. Status is observable. Lifecycle is controlled.
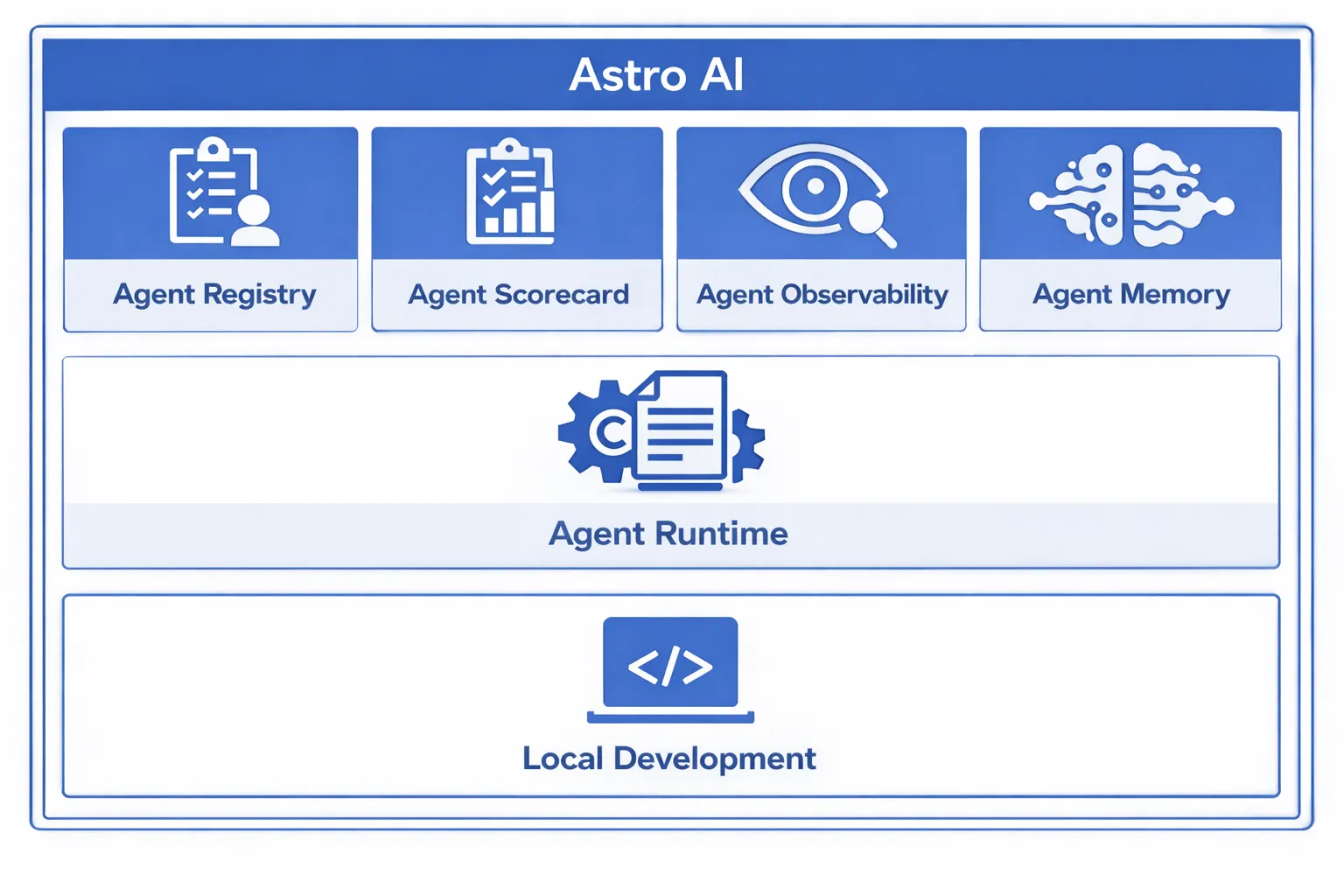
The platform enforces separation of responsibilities. Builders define behavior and constraints. Supervisors monitor runtime execution and enforce safety. Agent hiring managers evaluate ROI and make AI agent staffing decisions. Humans consume agents through interfaces suited to their workflow.
Astro AI includes built-in observability for execution tracing, tool invocation logging, guardrail enforcement visibility, and runtime metrics. The platform is model-agnostic. Your choice of model provider is independent of the packaging standard. Agents can run across environments and be consumed through HTTP, integrated via MCP, embedded in applications, or surfaced in collaboration tools like Slack or Teams. The runtime is portable and the interfaces are flexible.
Open Source Foundations
We are open sourcing the core packaging specification for describing and publishing complete working agents. We’re also open sourcing the Astro AI development experience, enabling you to bring your own agents, package them using the Astro AI specification, and publish them to the Astro AI agent registry.
This is about establishing a repeatable, inspectable, portable way to build agents that satisfy production constraints. Agents will continue to evolve rapidly. Models will improve. Tooling will expand. But without a shared operational foundation, organizations will continue to accumulate risk faster than they accumulate value.
We built Astro AI because we needed it. If you’re deploying agents with real credentials, connecting them to sensitive APIs, and scaling beyond prototypes, you probably need it too.
Now we are sharing it. Stay tuned for the open source drops at github.com/astropods.